Multimodal AI: Bridging Technologies, Challenges, and Future
Multimodal AI is an evolving concept in the domain of artificial intelligence. The multimodal AI is inspired by the human capability of experiencing the world in multiple ways, including seeing objects, hearing noises, feeling textures, and smelling odors. Unlike unimodal AI, multimodal AI can process various types of inputs like text, images, and audio and generate richer and more refined insights and responses. Most importantly, multimodal AI means several data sources are used simultaneously to create more efficient, accurate, and context-aware AI models. The enhanced capabilities of multimodal AI will elevate AI applications, including natural language processing, chatbots, computer vision, and speech recognition, to another level.
The forthcoming article will explore the workings of Multimodal AI, delve into the most prominent technologies, examine their applications, address the challenges they face, monitor their current market presence, and conclude.
What is Multimodal AI?
Multimodal AI combines many data types or modalities to make more accurate decisions, create insightful conclusions, or generate more precise forecasts regarding real-world problems. The system operates on text, images, audio, and many classic numerical data sets. Multimodal AI contains different modules related to text, audio, video, and images.
Applications of Multimodal AI
Multimodal AI combines different types of data, such as text, images, audio, and video, to create an effective and more flexible system for many applications. It can be used in various industries, such as healthcare, automotive, manufacturing, media, education, and many more. Multimodal AI is advancing fields such as autonomous driving, human-computer interaction, and sentiment analysis, making systems more sensitive and effective.
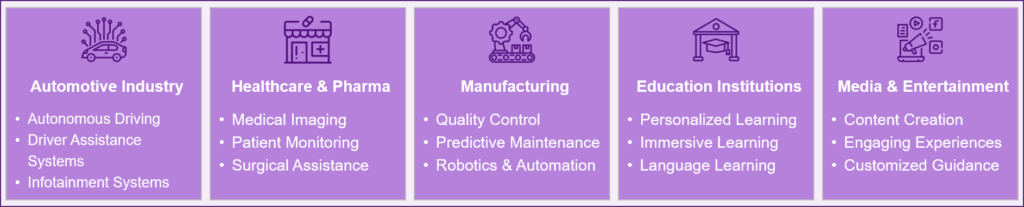
Figure 1: Application for Multimodal AI
How Does Multimodal AI Work?
Multimodal AI is used to generate content in different data types, such as text, images, and audio. The figure below indicates the typical multimodal AI framework. The framework includes four key components: the input module, the fusion module, the multimodal learning models, and the output module.
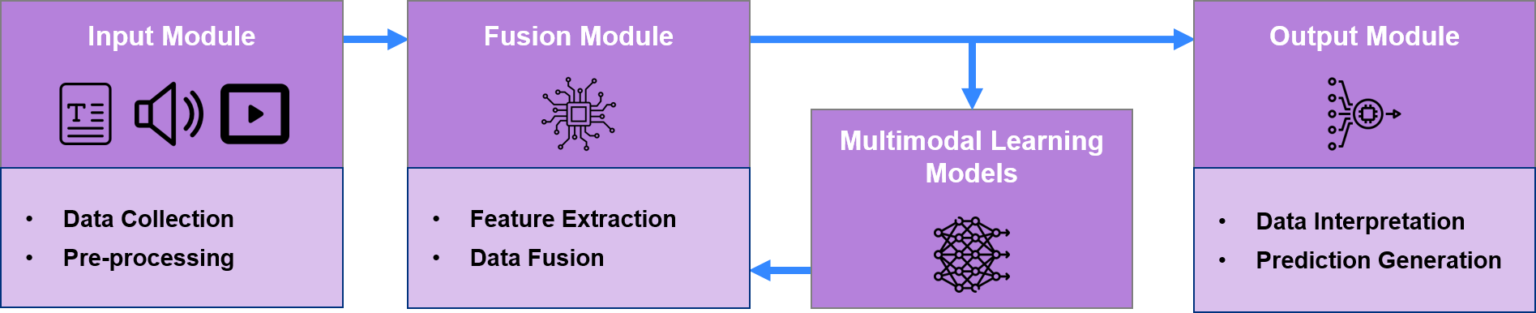
Figure 2: Working of Multimodal AI
Input Module
This module is a series of neural networks that are responsible for processing or encoding different types of data, such as speech, text, and vision. Generally, the input module performs the following operations:
- Data Collection: It gathers multiple data types such as text, images, audio, and video from various sensors (LIDAR, infrared cameras, or biometric sensors), devices (cameras, medical scans, or satellite imagery), and sources (documents, chat logs, or social media.).
- Pre-processing: Each modality faces pre-processing steps such as tokenization for text, resizing for images using CNN, and noise reduction for audio, which are applied to prepare the data for integration and analysis.
Fusion Module
The fusion module is the heart of the multimodal AI framework. The fusion module processes different types of datasets and creates a cohesive representation. The fusion module performs the following operations:
- Feature Extraction: In the feature extraction process, the fusion module extracts the relevant features from each data type (i.e., text, images, audio, etc.) using specialized algorithms and neural networks.
- Data Fusion: Some approaches commonly used for multimodal data fusion are Early Fusion, where multimodal data combines at the data level or input level; Late Fusion, where fusion occurs at the decision level or prediction level; and Intermediate Fusion, where data fusion occurs at any of the stages of training between input and final prediction.
Multimodal Learning Models:
Advanced models, such as transformers, multimodal neural networks, and attention mechanisms, process and learn from the fused data. These models are designed to handle and leverage the combined information efficiently.
Output Module
This module takes the unified representation produced by the fusion module and processes it through task-specific layers, such as fully connected layers or decoders. It generates the output in the desired format, such as text, images, or audio.
- Data Interpretation: It combines and integrates data from multiple sources, using techniques like attention mechanisms or concatenation to merge and balance the data effectively.
- Prediction Generation: It produces predictions in various formats (e.g., classifications, regressions, and sequence generations) to suit different tasks. It can generate predictions in different formats, including text, images, audio, etc.
Fusion Techniques
In Multimodal AI, three types of fusion techniques are mainly used to fuse or process the input data, simple operation-based, attention-based, and Bilinear Pooling-based methods

Figure 3: Types of Fusion Techniques
In the Fusion module, many techniques and methods are used to combine information from different modalities. Among them, transformer-based techniques have become prominent for fusion tasks due to their ability to capture complex dependencies and interactions across different modalities.
Transformer Architectures
Multimodal transformers are used to implement attention-based fusion due to their ability to handle complex processes between different modalities. Transformers handle different data types to create a single model that can learn from video, audio, and text. Figure 4 indicates a typical multimodal transformer architecture composed of a single Transformer Encoder on which three distinct forward calls are made.
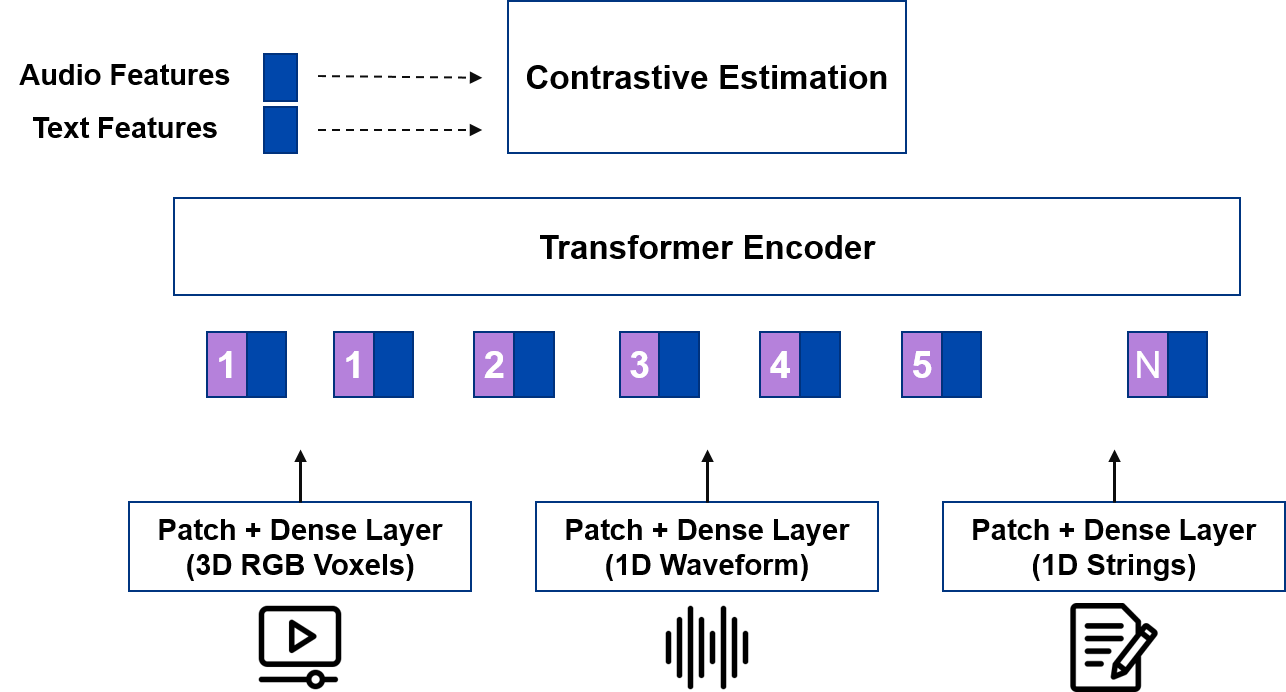
Figure 4: Multimodal Transformer Architecture
Using a single call, all kinds of input data are converted into a sequence of tokens. The transformer takes these sequences as input and returns three different sets of features. Then, the features are sent as input to a contrastive estimation block that calculates a single loss and performs the backward. The loss results from the error focused on all three types of data. Therefore, between the epochs, the model will learn to reduce it by better managing the information coming from all three sources.
Contrastive Estimation: It provides training to the modals to learn representation that can differentiate between different modalities (such as images and text) by maximizing similarity within modalities and minimizing similarity across modalities. This method helps the transformer integrate and process many data types, improving its ability to accurately understand and generate multimodal content.
Transformer Encoder: It generates contextualized representations of each modality’s features, facilitating effective fusion and integration of information across modalities in subsequent model layers. This enables the transformer to understand and generate comprehensive multimodal outputs based on combined input data.
What Are the Challenges & Solutions in Multimodal AI?
Multimodal AI technology suffers from many challenges, such as handling different types of data and aligning them properly, as well as overcoming difficulties in training complex models efficiently, to overcome these challenges. Some innovative solutions, which represent the advancements, are given below.
Challenge:
Data Alignment and Synchronization –Building a good multimodal model starts with a good dataset. However, creating diverse and high-quality multimodal is a primary challenge as the different types of data (e.g., text, audio, images, etc.) have different features, and each type of data type requires specific pre-processing steps for data cleaning, normalization, and making the data ready for integration.
Solutions:
- Joint Multimodal Learning using Multimodal Transformers: Using transformers to learn joint representations of different datatypes. The attention mechanisms in transformers can be used to align data from different sources by focusing on the relevant parts of each data type.
- Cross-Modal Autoencoders: Autoencoders can be extended to cross-modal settings where the encoder and decoder operate on different modalities. The model learns to align and map features from one modality to another, effectively synchronizing multimodal data.
Challenge:
Model Complexity and Training—Designing sophisticated multimodal AI models is complex as they require advanced AI architectures like transformers, capsule networks, memory networks, and others. These architectures require a large amount of labeled training data for each datatype, which is costly and consumes a substantial amount of time to gather and label the data.
Solutions:
- Modular Networks for Multimodal Learning: Modular networks consist of multiple sub-networks, each specialized for a specific modality. These sub-networks are trained separately and then combined through a higher-level network that integrates their outputs. This approach simplifies training and improves scalability.
- Hierarchical Multimodal Networks: Hierarchical networks process data at multiple levels of abstraction. Lower layers handle modality-specific features, while higher layers integrate these features into a unified representation. This hierarchical approach manages complexity and enhances the model’s ability to learn from multimodal data.
Challenge:
Computational Resources and Infrastructure –Training and deploying a multimodal AI model requires a large amount of computational resources and specialized infrastructure to effectively perform real-time computation with diverse data streams.
Solutions:
- Edge Computing with Federated Learning: Using the computation capabilities of the edge devices for local computation substantially reduces the load on the central servers and improves the scalability of the multimodal AI framework. Edge computing with federated learning enables the models to train across multiple devices while keeping data localized, enhancing privacy, and reducing data transfer costs.
- Hardware Accelerators and Specialized Chips: Customized hardware accelerators like Tensor Processing Units (TPUs) and Neural Processing Units (NPUs) can be utilized to optimize the performance of multimodal AI framework at the edge devices by reducing the time and energy required for training and local computations.
- Efficient Transformer Architectures: Utilization of advanced transformer architectures like Linformer and Performer can reduce the computational complexity of the attention mechanism and make the training and deployment of large multimodal models.
Challenge:
Privacy and Ethical Concerns – Multimodal AI models need to integrate data from many sources, such as healthcare records, social media, wearables, smartphones, etc. Multisource data integration raises serious privacy concerns, especially when dealing with sensitive information.
Solutions:
- Differential Privacy Techniques: This approach introduces noise to the data or the model training process, ensuring that the privacy of specific data points needs protection. Differential privacy can be integrated into multimodal AI systems to safeguard sensitive information.
- Ethical AI Frameworks & Regulatory Compliance: The development of ethical guidelines and regulatory compliances for AI development can ensure that multimodal AI systems are designed fairly and transparently.
Market Activity
The market for multimodal AI is witnessing dynamic activity, with various companies launching innovative products. Key players such as Meta, Apple, Google, Microsoft, and others have introduced comprehensive platforms integrating text, image, and speech processing for diverse applications.
| Company | Key Details |
| Eleven Labs | In June 2024, Infer.so partnered with ElevenLabs to create the Multimodal AI voice bot, revolutionizing industries like e-commerce and fintech with lifelike voice interactions. |
| Apple | In March 2024, Apple launched its first Multimodal AI Model, MM1, revolutionizing Siri and iMessage by understanding images and text contextually. MM1 could also help users understand the context of shared images and texts within iMessage, offering them more relevant suggestions for responses. |
| Meta | In January 2024, Meta began testing a GPT-4V rival multimodal AI in Ray Ban smart glasses made in partnership with the signature eyewear company, Ray Ban In August 2023, Meta launched SeamlessM4T, a Multimodal AI Model for Speech and Text Translations. |
| Renesas | In December 2023, Renesas introduced RA8 MCU Group, Targeting Graphic Display Solutions and Voice/Vision Multimodal AI Applications |
| In December 2023, Google announced its latest AI model, Gemini. From the start, it was built to be multimodal to interpret information in multiple formats, including text, code, audio, image, and video | |
| Reka | In October 2023, Reka launched Yasa-1, a multimodal AI assistant, to take on ChatGPT. Reka is an AI startup founded by DeepMind, Google, and Meta researchers. |
| Azure | In October 2023, Microsoft Azure AI introduced Idea2Img, a Self-Refinancing Multimodal AI Framework for automatically developing and designing images |
| Microsoft | In February 2023, Microsoft launched Kosmos-1, a multimodal model that can reportedly analyze images for content, solve visual puzzles, perform visual text recognition, pass visual IQ tests, and understand natural language instructions. |
Ecosystem
The market adoption of Multimodal AI consists of various key players, each playing a distinct role in advancing the field of AI and software development. The prominent key players for Multimodal AI are listed below.

Figure 5: Key Players of Multimodal AI
DeepSeek’s Multimodal AI Model
DeepSeek AI is making headlines with its advancements, precisely with its multimodal AI model Janus Pro. It is set to impact the field of multimodal artificial intelligence which can be assessed through various key aspects, including performance benchmarks, accessibility, architectural innovation, and competitive dynamics in the AI landscape.
It may pave the way for more versatile applications across industries such as healthcare, entertainment, and education.
Conclusion
Multimodal AI demonstrates the revolutionary impact of converging technologies. Its capacity to smoothly integrate many sensory inputs opens up new possibilities for AI applications, improving human-machine interaction. However, difficulties such as data integration complexities and ethical concerns necessitate cautious navigation. Despite these challenges, market activity reveals a dynamic ecosystem with significant interest and investment.
Let's Take the Conversation Forward
Reach out to Stellarix experts for tailored solutions to streamline your operations and achieve
measurable business excellence.


